Building Reliable AI Pipelines: Error Handling, Retries, and Fallbacks in Backend AI Development
In modern backend AI development , building a reliable AI pipeline has become one of the hardest engineering challenges. It is no longer optional; it is a critical requirement for production to ensure stability at scale.
While large language models (LLMs) offer unprecedented capabilities, their raw integration into mission-critical workflows introduces profound risks.
A raw LLM is effectively a CPU without RAM or I/O—it cannot operate safely on its own.
A raw LLM is effectively a CPU without RAM or I/O—it cannot operate safely on its own.
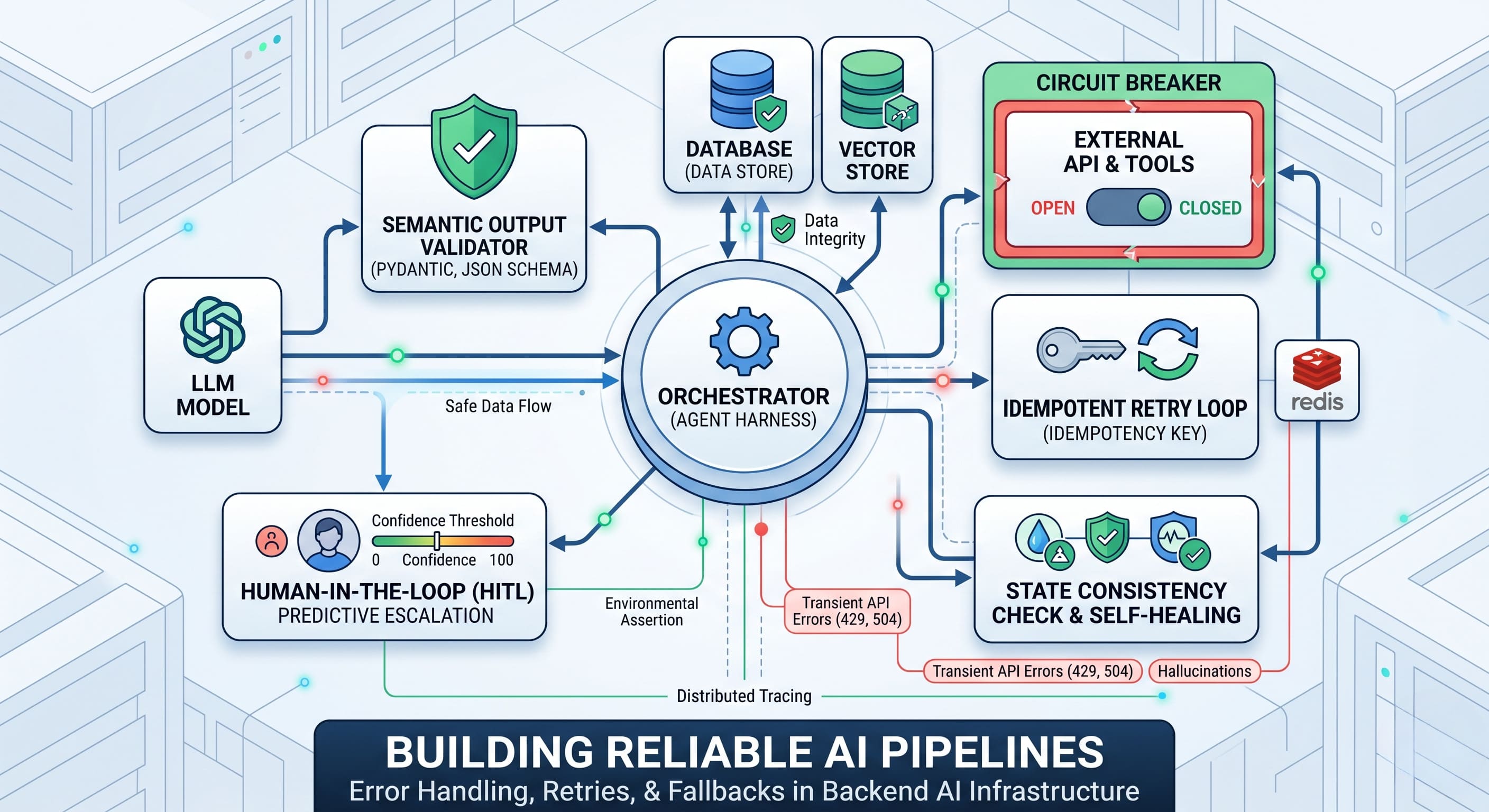
To function safely within an agent-based AI system, an LLM requires a robust "Agent Harness." This is the complete software infrastructure wrapping the model, encompassing the orchestration loop, tools, memory, and error recovery.
Without a resilient harness, a single unhandled timeout or semantic hallucination can lead to data corruption, silent failures, or catastrophic medical errors. To transition from experimental prototypes to production AI systems, developers must prioritize rigorous implementation and resilience strategies.
This leads to a critical question: how do we structure these safety nets? This article explores the anatomy of AI failures and outlines the architectural patterns required to build fault-tolerant, dependable AI systems.
The Problem: Why Traditional Error Handling Fails in Modern AI Pipelines
In conventional software engineering, errors are mostly deterministic and reproducible. They are easily trapped using standard try/catch blocks. However, AI agents operate on probabilistic foundations within highly dynamic environments.
When building LLM pipelines, engineers face a unique blend of failures:
- Execution and Dependency Errors: Agents heavily rely on third-party APIs and external tools. They frequently encounter transient network issues, API rate limits (HTTP 429), or gateway timeouts (HTTP 504). In a complex AI pipeline, these dependencies create multiple single points of failure.
- Semantic Errors (Hallucinations): An LLM might generate a response that is syntactically valid but factually or logically incorrect. For example, a model might correctly format a JSON payload but hallucinate a nonexistent file path or prescribe an incompatible medical treatment.
- State Desynchronization: Autonomous agents executing multi-step plans can easily fall out of sync with the actual environment. If an AI pipeline assumes a database record was updated when the underlying execution actually failed, every subsequent step builds on a faulty premise.
Without defensive architecture, these failures compound rapidly. A simple network timeout can trigger aggressive retry loops that overwhelm servers (a "retry storm"), or worse, execute a critical side effect twice.
The Solution: Resilient Patterns for Backend AI Development in AI Pipelines
To combat these vulnerabilities, engineering teams must implement a multi-layered fallback architecture that protects the network, the data state, and the semantic output. These are among the engineering realities no framework prepares you for.
A typical resilient AI pipeline flow looks like this: Orchestrator → Circuit Breaker/Retry Layer → LLM & External Tools → Validator → State Verification
To manage this complexity, deep observability is essential. Engineers must implement comprehensive logs, distributed tracing, and metrics tracking (e.g., failure rates, retry counts) to monitor the system's health. Without observability, even well-designed AI pipelines become opaque systems where failures cannot be diagnosed or prevented.
With observability in place, we can apply four core patterns:
1. Intelligent Retries and Atomic Idempotency
The first line of defense against transient API errors is implementing automatic retries with exponential backoff. However, blindly retrying requests is highly dangerous in distributed systems. A timeout only means the client didn't receive a response—not that the server didn't process the request.
To address this, retries must be paired with Idempotency Keys. By generating a unique identifier for a specific user intent, the agent guarantees that side effects execute at-most-once. The server uses atomic locking to claim the key before processing:
Idempotency-Key: 550e8400-e29b-41d4-a716-446655440000
SET key NX EX 300If two identical requests arrive simultaneously due to a network stutter, this atomic lock ensures only the first is processed.
2. Proactive Circuit Breakers vs. Reactive Fallbacks
While fallbacks are standard practice, they are intrinsically reactive. If the primary provider is suffering an outage, the system waits for a timeout on every single request before routing to the secondary model, creating compounding latency.
A Circuit Breaker is proactive. It monitors the failure rate and specific status codes over time. If the error threshold is crossed, the circuit "trips" and removes the unhealthy provider from the routing pool for a cooldown period. During this "Open" state, all traffic routes instantly to the fallback model. This preemptive cutoff stops retry storms and maintains minimal added latency.
3. Semantic Validation and State Self-Healing
Because LLMs are non-deterministic, their outputs must never be trusted blindly. Reliable agentic systems enforce strict output schemas using constraint libraries like Pydantic. If validation fails, the output is dynamically routed to a specialized "sanitizer agent" to correct the structure before passing it downstream.
To combat state errors, agents must also utilize environment-based verification. After executing critical actions, the agent runs assertions to verify changes actually took place. If the environmental state diverges from expectations, the system triggers a re-plan or rollback.
4. Human-in-the-Loop (HITL) Predictive Escalation
The ultimate safeguard for high-stakes workflows is human expertise. Modern HITL systems do not wait for a catastrophic failure. Instead, they use predictive escalation based on anomaly detection, sentiment analysis, and confidence thresholds.
If the AI's statistical confidence drops below a typical threshold (e.g., 85%), the system triggers a seamless transfer to a human expert. Advanced routing targets a handoff of under 500 milliseconds, passing the full context so the transition remains invisible to the end user.
| Pattern | Failure Addressed | Mechanism |
|---|---|---|
| Intelligent Retries & Idempotency | Transient API errors, duplicate side effects | Exponential backoff with atomic idempotency keys |
| Circuit Breakers | Provider outages, retry storms | Proactive tripping and routing to fallback model |
| Semantic Validation & Self-Healing | Hallucinations, state desync | Strict schemas, sanitizer agents, environment verification |
| Human-in-the-Loop Escalation | Low-confidence, high-stakes outputs | Predictive escalation to human experts |

Real Example: Securing a Medical Transcription & Reporting Agent
To see how these strategies coalesce in production, consider a Healthcare AI Agent utilized by surgeons. The system ingests live audio, transcribes the operation, generates a structured medical report, and provides a conversational interface for the doctor to edit the report. It also maintains a vector history of all transcriptions for generating insight reports.
This is a high-stakes environment where failures are unacceptable.
Execution Risk
When the doctor finalizes a large batch of reports, the database connection times out. Instead of failing or blindly retrying (which could create duplicate patient records), the agent utilizes its Idempotency-Key architecture. The retry safely recognizes that the records were already saved, preventing data duplication.
Later, the primary LLM provider experiences latency spikes. The system's circuit breaker observes the rising failure rate and trips, preemptively routing the query to a faster fallback model without waiting for timeouts. In our deployments, this circuit breaker pattern routinely reduces failed requests by up to 42% during provider degradation.
State & Semantic Risk
In the chat interface, the doctor instructs the agent: "Update the surgical notes to reflect a 50mg dosage".
If the model generates malformed JSON, strict schema validation catches it instantly and routes it to a sanitizer agent. To prevent state desynchronization, the agent performs environment-based verification: it actively queries the database to confirm the dosage field actually reads "50mg" before replying to the doctor that the update was successful.
Escalation Risk
While summarizing historical data, the fallback model successfully returns a payload, but its statistical confidence regarding a specific procedural outcome is only 81%.
Because patient records are strictly regulated, the HITL protocol is instantly triggered. Within milliseconds, the flagged report segment and the historical context are highlighted and escalated for mandatory human review, significantly reducing the risk of medical hallucinations entering the final report.
The Result: Trust, Efficiency, and Scale
By replacing fragile, monolithic AI wrappers with robust, distributed Agent Harnesses within the AI pipeline, organizations achieve remarkable outcomes. Enterprises deploying mature human-in-the-loop and automated resilience strategies often report up to 30% productivity gains, all while maintaining accuracy levels that exceed traditional workflows.
Furthermore, customer satisfaction scores can rise significantly, as users experience near-perfect uptime and seamless fallback mechanisms that mask underlying AI infrastructure complexities. Ultimately, implementing these safety nets shifts AI from a high-risk experiment into a dependable engine for enterprise innovation.
- Up to 30% productivity gains from mature resilience and human-in-the-loop strategies
- Accuracy levels that exceed traditional workflows
- Higher customer satisfaction from near-perfect uptime
- Seamless fallback mechanisms that mask underlying AI infrastructure complexity
Ready to Future-Proof Your AI Pipeline?
Building reliable AI pipelines requires more than just integrating an LLM—it demands robust architecture, fault tolerance, and deep backend AI development expertise.
Visit https://ego-digital.com to see how we design and scale production-grade AI pipelines—and how quickly we can help you move from prototype to reliable production, particularly in regulated industries.
Do you have any questions about Product Design & Development?
Ask Oleksandr Konyk – Backend AI Developer!
Recent Articles


Your AI Is Quietly Moving Your Data Across Borders
In the age of AI, data sovereignty is about control — not location.

Observability and Analytics: You Can't Deploy an Agent You Can't See
An autonomous agent in a demo looks like magic. The same agent in production, three weeks later, is often quietly pulled back out. The gap between those two moments is almost never the model. It is whether anyone could actually see what the agent was doing.

Your Next Competitor Has No Capital
Every few weeks, someone asks me whether AI is a bubble. Usually it's a sharp person — an investor, a board member, a fellow founder — and they ask while glancing at a stock chart that has gone vertical. It's a fair question. It's also aimed at the wrong object.
THE FUTURE IS AI-NATIVE.
LET'S BUILD IT WITH YOU.
Partner with us to design and deploy AI-native systems.