LLM Orchestration in Production: The Engineering Realities No Framework Prepares You For
Most teams shipping their first AI agent discover the same uncomfortable truth: the demo that wowed everyone in the all-hands meeting falls apart the moment real users touch it. LLM orchestration in production is not a harder version of prototyping — it is a fundamentally different discipline.
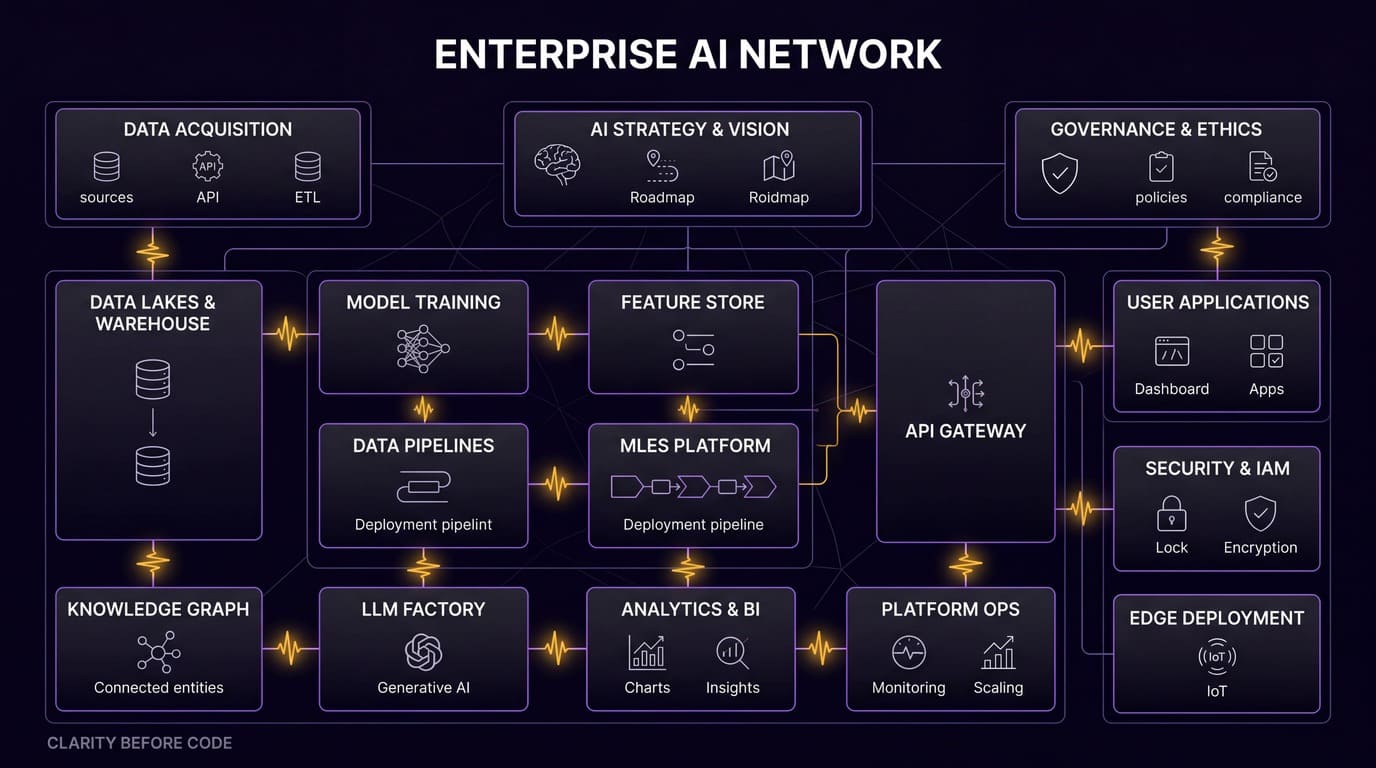
The frameworks are loud about how easy it is to chain a few prompts together. They are quiet about what happens at 2 a.m. when a model provider degrades, a tool call times out mid-loop, and your agent has spent $40 retrying the same broken JSON parse. At EGO Digital, we have built and rebuilt enough production AI systems to know exactly what that quiet part sounds like. This article is about that.
The Problem: The Gap Between Demo and Production
A working prototype of a multi-step agent tells you almost nothing about whether it will survive production. Three forces conspire against you the moment you ship.
Latency compounds. A single LLM call at p50 of 1.2 seconds feels instant. Chain six of them with tool calls in between and you are looking at a 15-second response on a good day, 45 seconds on a bad one. Users do not wait 45 seconds. They refresh, retry, and double your traffic.
Failure modes multiply. Every node in your production AI pipeline can fail independently: the model returns malformed JSON, the vector store times out, a tool call hits a rate limit, a downstream API returns a 502, the context window overflows because a retrieved document was larger than expected. In a six-step agent, you are not dealing with one failure mode — you are dealing with the Cartesian product of all of them.
Costs are non-linear. Retries, fallback models, expanded context on second attempts, and silent infinite loops can turn a $0.04 expected cost per request into a $4 actual cost. We have seen a single misconfigured AI agent burn through a month's budget in 11 hours.
Most orchestration tutorials show you the happy path. Production is the unhappy path — with telemetry attached, if you are lucky.
The Solution: Treat Orchestration as a Distributed Systems Problem
Our guiding principle at EGO Digital is Clarity Before Code. Before writing a single line of agent logic, we map the failure surface, define budget boundaries, and establish observability contracts. This discipline — applied across every AI engagement we run through the Mashu AI orchestration layer — is what separates systems that hold up under load from systems that get quietly switched off after the first production incident.

Once you start thinking of an agent as a distributed system with non-deterministic nodes rather than a clever script, the playbook becomes familiar.
Make every step idempotent and resumable. If your agent fails on step 4 of 6, you should not have to re-run steps 1–3. We persist intermediate state — the plan, the tool results, the partial reasoning — to a durable store keyed by a request ID. On retry, the orchestrator picks up where it left off. This single architectural decision cut our average cost-per-failed-request by roughly 70%.
Persisting intermediate state so retries resume instead of restart cut average cost-per-failed-request by roughly 70%.
Bound everything. Every loop gets a maximum iteration count. Every tool call gets a timeout. Every total request gets a budget cap in both tokens and dollars. When a budget is hit, the agent exits gracefully with a partial result and a clear error — not a 500. This is not just good engineering; for enterprise deployments with compliance obligations, it is a hard requirement.
Route to the cheapest model that works at each step. Model routing is the most underrated cost lever in LLM orchestration. Classification and extraction tasks rarely need a frontier model. We typically run a lightweight model for intent detection and structured extraction, then escalate to a more capable model only for the synthesis step where reasoning quality actually matters. On one recent workflow, this routing strategy reduced cost by 62% with no measurable quality drop on our evaluation set.
Validate structured output at the boundary. Do not trust the model to return clean JSON. Use a schema validator — Pydantic, Zod, or JSON Schema — with a retry-on-failure loop bounded to two attempts. If both fail, fall back to a deterministic parser or return a structured error. Never let malformed output propagate downstream; it will surface as a confusing bug three steps later, and in regulated industries like fintech or healthcare, it can surface as a compliance incident.
Instrument like you mean it. Every span needs: request ID, step name, model used, input tokens, output tokens, latency, cost, and outcome. Without this, debugging a misbehaving agent is archaeology. With it, you can answer "why did this request cost $2.30?" in under a minute. Mashu AI ships with this observability layer built in — structured traces, cost accounting, and anomaly alerts — so teams are not building telemetry from scratch on top of every new workflow.
| Engineering Principle | What It Prevents | Measured Impact |
|---|---|---|
| Idempotent & Resumable Steps | Re-running already-successful steps after a failure | ~70% lower cost per failed request |
| Bounded Loops & Budgets | Runaway iterations and uncontrolled token/dollar spend | Graceful exit with partial result instead of a 500 |
| Model Routing by Task | Using a frontier model for simple classification/extraction | 62% cost reduction with no measurable quality drop |
| Schema Validation at Boundaries | Malformed JSON propagating into downstream steps | Avoids bugs and compliance incidents in regulated industries |
| Full Observability Instrumentation | Untraceable cost, latency, and failure spikes | Root-cause analysis of request cost in under a minute |
A Real Example: The Logistics Document Agent
We recently built a multi-agent system for a logistics client that ingests shipping documents — bills of lading, customs forms, packing lists — and reconciles them against the client's internal order system. Sounds like a classic OCR-plus-LLM pipeline. It was not.
The first version was a monolithic agent with five tools: extract text, classify document type, parse fields, look up the order, write the reconciliation result. It worked in the demo. In production, it failed on roughly one in four documents. The failures clustered around three issues: documents in mixed languages broke the classifier, fields appeared in wildly inconsistent positions across carriers, and the agent would occasionally loop forever trying to reconcile a partial match.
The rebuild followed every principle outlined above. We decomposed the monolithic agent into three specialized agents — an extractor, a classifier, and a reconciler — each with its own model tier, timeout budget, and output schema. The orchestration layer running on Mashu AI managed state handoffs between agents, enforced iteration limits on the reconciler, and surfaced partial failures with enough context for a human reviewer to step in. Document processing failure rate dropped from 25% to under 3%. Average cost per document dropped by 58%.
The architecture was not clever. It was disciplined.
Enterprise-Grade Orchestration Is Not Optional
For CTOs and engineering leaders building AI into core workflows, the question is no longer whether to use LLM orchestration — it is whether your orchestration layer is robust enough to carry production load, satisfy compliance requirements, and scale without becoming a liability.

At EGO Digital, we have been building and operating production AI systems since 2011, and our IBM Platinum Partnership gives us access to enterprise-grade infrastructure and security controls that most AI vendors cannot match. Whether you are in logistics, fintech, healthcare, or e-commerce, the engineering principles are the same — only the compliance surface changes.
The systems that last are the ones built on evidence, not intuition. On bounded, observable, resumable pipelines — not hopeful scripts.
Ready to move from fragmented AI tools to an orchestrated enterprise ecosystem? Talk to an EGO Digital expert →
Do you have any questions about Engineering & Infrastructure?
Ask Denis – AI Product Architect!
Recent Articles


Your AI Is Quietly Moving Your Data Across Borders
In the age of AI, data sovereignty is about control — not location.

Observability and Analytics: You Can't Deploy an Agent You Can't See
An autonomous agent in a demo looks like magic. The same agent in production, three weeks later, is often quietly pulled back out. The gap between those two moments is almost never the model. It is whether anyone could actually see what the agent was doing.

Your Next Competitor Has No Capital
Every few weeks, someone asks me whether AI is a bubble. Usually it's a sharp person — an investor, a board member, a fellow founder — and they ask while glancing at a stock chart that has gone vertical. It's a fair question. It's also aimed at the wrong object.
THE FUTURE IS AI-NATIVE.
LET'S BUILD IT WITH YOU.
Partner with us to design and deploy AI-native systems.