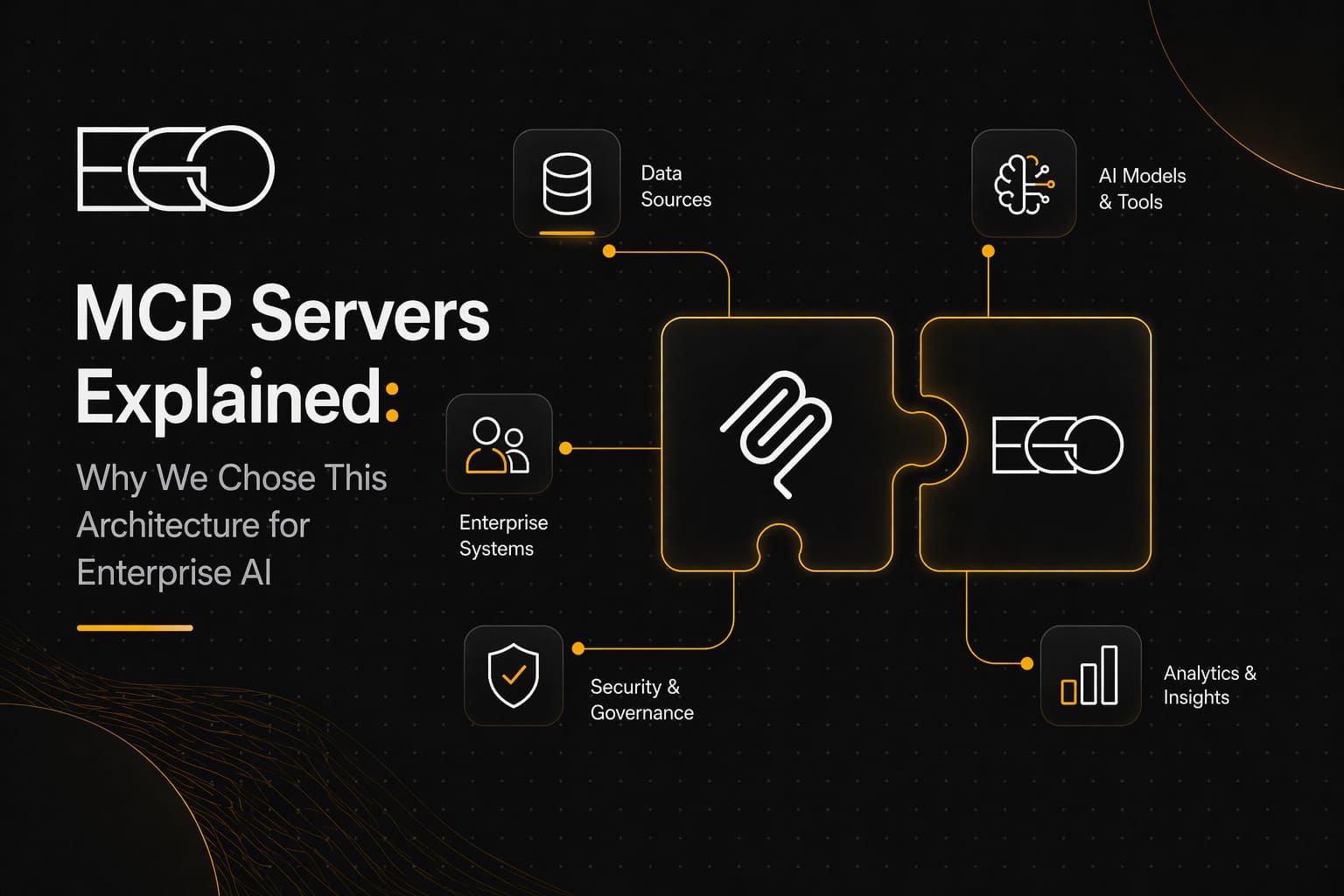
MCP Servers Explained: Why We Chose This Architecture for Enterprise AI
A few months ago, one of our engineers asked a question that had been bothering me for a while: "Why are we writing the same integration glue for every new AI agent we ship?" He was right. Every new project meant another bespoke connector to Jira, another adapter for Figma, another wrapper around our internal APIs. Multiply that by a few clients and a dozen tools each, and you end up maintaining a small zoo of one-off integrations. That is the moment we made a deliberate move to MCP servers as the backbone of our enterprise AI architecture, and this article is a practical look at why, including how we are using them in real client work and inside our own Momentum platform.
What MCP Servers Actually Are (Without the Hype)
The Model Context Protocol, which everyone now calls MCP, is a standardized contract between LLM-driven agents and the tools they need to use. Instead of teaching every agent how to talk to every system through custom prompts and brittle function definitions, you expose a system once as an MCP server, and any compatible agent (Claude, Cursor, a custom orchestrator, our own runtime) can use it.
For us at EGO Digital, the appeal was never the protocol itself. What matters is what MCP forces you to do as an architect: treat every enterprise capability (a Jira project, a Figma file, a GitHub repository, an internal microservice) as a typed, documented, permissioned interface for AI consumption. That mental shift turned out to be more valuable than the JSON schema.
The Problem We Were Trying to Solve
Enterprise AI lives or dies on integration. You can have the smartest model in the world, but if it cannot safely read a Jira ticket, fetch a design from Figma, or write a record to your domain backend, it is a chatbot
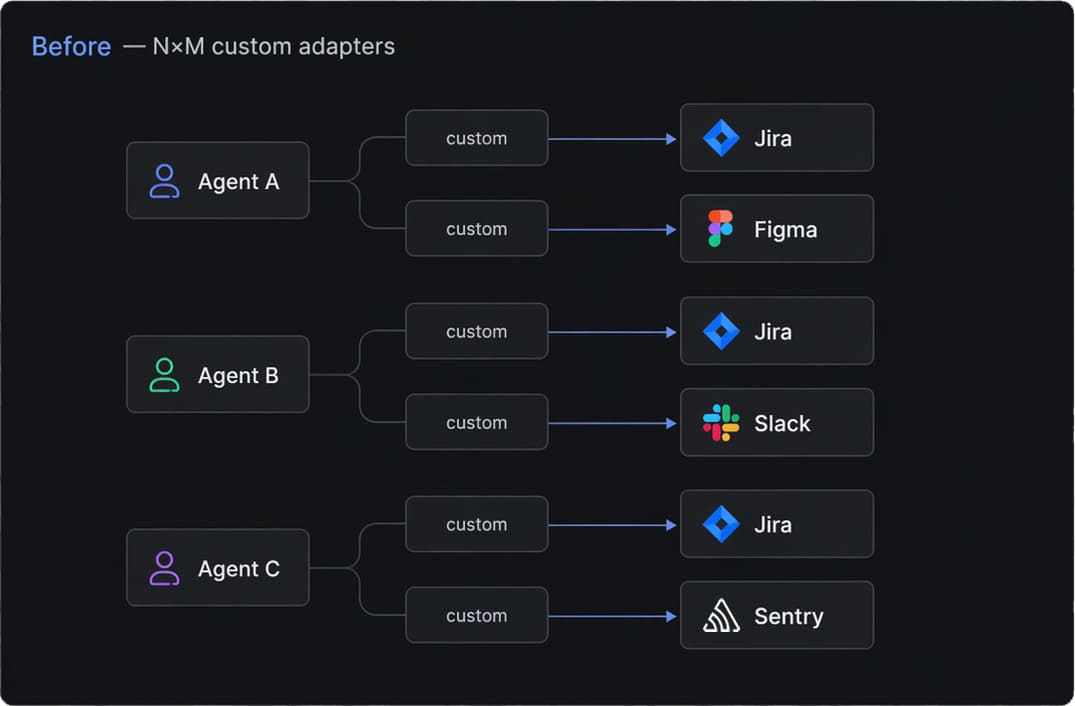
Before MCP, our typical project looked like this:
- An agent prompt full of "if the user asks about Jira, call this function with these parameters."
- A growing pile of HTTP wrappers, each with its own error handling, retries, and auth quirks.
- A separate set of integrations for every new agent runtime, because formats never quite matched.
- Constant tension between giving the model enough freedom and preventing it from doing something unauthorized.
Every new agent meant a new round of integration work, and security reviews started almost from scratch each time, because there was no consistent layer to point at and say "this is where access control lives."
Why MCP Won the Internal Argument
We did evaluate alternatives: hand-rolled tool registries, an in-house function-calling spec, gateways like LangChain Tools. They all worked, but they all had the same problem: they were ours. As soon as a client brought their own AI runtime, or a new model vendor shipped a better orchestrator, we were on the hook to maintain the bridge.
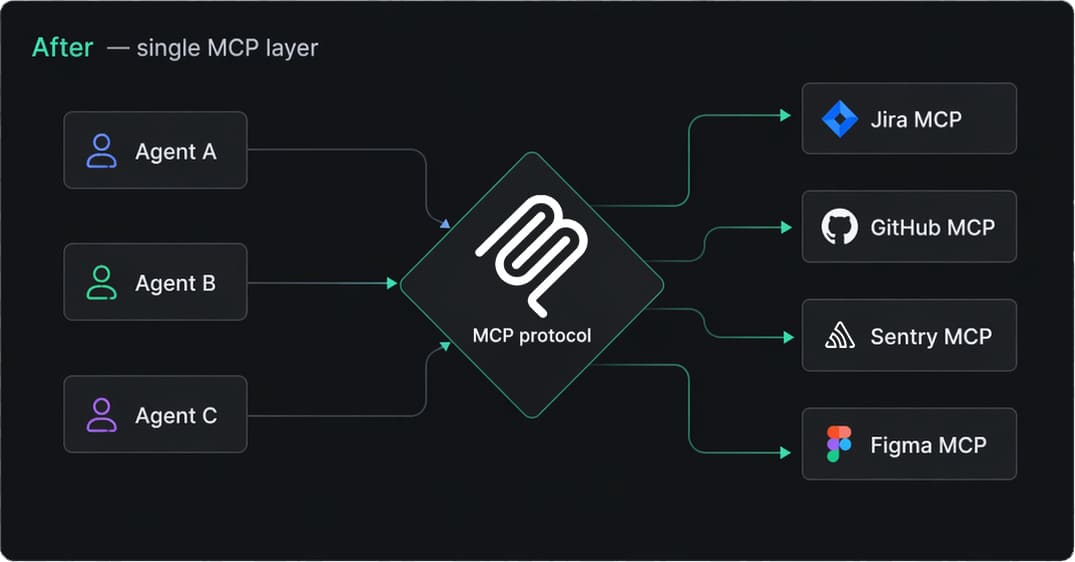
MCP solved that. By committing to a protocol already being adopted across the major model vendors and IDE tooling, we got three things almost for free through MCP servers and integrations:
- Reusability. A server we build once works in Claude Desktop, Cursor, our own agents, and any future tool that speaks MCP.
- A clear security boundary. Each MCP server is where authentication, scopes, and audit logging live. Agents do not hold tokens; servers do. That alone makes compliance conversations much easier with regulated clients.
- Composability. Complex workflows become small servers wired together, each independently testable and owned by a specific team.
Agents do not hold tokens; servers do. That alone makes compliance conversations much easier with regulated clients.
MCP is not magic, of course. A poorly designed MCP server is just another bad integration with a fashionable label.
How We Use MCP Servers Day to Day
Most of our engineering pipeline now sits behind a small set of MCP servers shared across teams.
Jira is the visible one. Creating, refining, and linking issues happens directly from chat or from the IDE. A developer can say "split this into three tickets under MMAI-204, assign them to me, and link the parent" and the agent does it through the Jira MCP server, with every call logged on the server side instead of inside a prompt.
GitHub is where we get the most day-to-day value. The same agents that draft tickets also open pull requests, leave first-pass review comments on diffs, and check CI status through the GitHub MCP server. When a PR fails on a flaky test, an agent triages it before a human looks. Agents do not merge (that stays a human decision), but almost everything around the merge button is now mediated by MCP.
Sentry closes the loop. When a new error spikes in production, the on-call agent pulls fresh stack traces through the Sentry MCP server, correlates them with recently merged GitHub PRs, and either drafts a Jira ticket or pings the engineer. Each call is a typed operation on a server that already knows what scopes the agent has.
Figma covers the other half of our delivery. Our design and frontend teams use the Figma MCP server to pull components, frames, and design tokens into the implementation workflow. The agent reads a frame, extracts the relevant variables, and proposes a component that matches the design system instead of approximating it. That alone cut a lot of "the implementation does not look like the mock" cycles.
None of these is exotic. That is the point. The value of MCP shows up in the boring, repetitive parts of the day, where it removes friction at scale.
| MCP Server | What agents do through it |
|---|---|
| Jira | Create, refine, link, and assign issues |
| GitHub | Open PRs, leave first-pass reviews, check CI status |
| Sentry | Pull stack traces and correlate with merged PRs |
| Figma | Pull components, frames, and design tokens |
Building Our Own Internal MCP Servers
Public MCP servers like Jira, GitHub, Sentry, and Figma are great for the connective tissue of a development team. The bigger architectural decision is what to do with your own backend.
Our systems are organized around bounded contexts. When we started exposing those to agents, the temptation was to wrap "the API" as one big MCP server. We did not. Instead, we ship one thin MCP server per bounded context, sitting on top of the corresponding domain services.
Two reasons this matters:
- An agent only sees operations that make sense for its job. The blast radius of a misbehaving model is bounded by the surface we chose to expose.
- The contract is owned by the team that owns the domain. They can add, deprecate, and version operations without coordinating with every agent author.
This is where we spend most of the design time, and it has the longest payoff.
A Real Case: The Momentum Psychological Support Agent
The clearest example of this pattern comes from Momentum, a platform we are building that includes a psychological support agent for end users.
The agent's job is to hold a careful conversation, recognize when something serious is happening, and register a crisis event in the backend when needed so the right people can act. That last step is non-negotiable. If the agent decides a situation qualifies as a crisis, the event has to land in the database with the right metadata, every single time, and only when the agent is genuinely authorized.
We exposed the relevant slice of the Momentum backend through a dedicated MCP server. The agent does not see the full API surface, does not hold long-lived credentials, and cannot touch tables it has no business with. It sees a small, deliberate set of operations: create a crisis event, attach context, look up an existing case under tightly scoped conditions. Everything else is invisible to it.
What this gave us:
- Safety. The MCP server is the single place where validation, authorization, and rate limiting happen. The agent can hallucinate all it wants; the server refuses anything outside its contract.
- Auditability. Every call is logged at the server boundary, with the conversation context, the parameters, and the outcome. For psychological support, that is the foundation of trust with the clinical team.
- Replaceability. If we swap the model or add a second agent that needs the same capability, none of the backend code changes. The MCP server is the stable interface.
The clinical and product team can read the server's tool definitions and see exactly what the agent is allowed to do. That alone has shortened our review cycles dramatically.
What Changed for Us
A few months in, the practical results are easy to summarize:
- New integrations take days, not weeks, because we mostly compose existing servers instead of writing connectors from scratch.
- Security reviews have a single, obvious target. Conversations that used to span ten files now happen around one server definition.
- We finally have a clean separation between things that change quickly (models, prompts, orchestration) and things that should change slowly (business contracts, data access, compliance).
That last point is the one I care about most. Enterprise AI projects fail when those two layers are tangled together. MCP, used with discipline, keeps them apart.
Enterprise AI projects fail when those two layers are tangled together. MCP, used with discipline, keeps them apart.
Where to Go From Here
If you are starting on enterprise AI in 2026, my honest recommendation is to treat MCP servers as a default architectural choice, not a clever optimization for later. The cost of adopting it early is small. The cost of retrofitting it onto a year of bespoke integrations is not.
At EGO Digital we design, build, and operate this orchestration layer for clients across logistics, healthcare, fintech, and internal enterprise platforms through our enterprise AI integration work. If you are trying to figure out where MCP fits in your stack, we are happy to talk.
Read more about how we approach this work at ego-digital.com.
Nikita
AI Systems Architect, EGO Digital
Do you have any questions about MCP Servers & Integrations?
Ask Nikita – Intelligent Systems Architect!
Recent Articles


Your AI Is Quietly Moving Your Data Across Borders
In the age of AI, data sovereignty is about control — not location.

Observability and Analytics: You Can't Deploy an Agent You Can't See
An autonomous agent in a demo looks like magic. The same agent in production, three weeks later, is often quietly pulled back out. The gap between those two moments is almost never the model. It is whether anyone could actually see what the agent was doing.

Your Next Competitor Has No Capital
Every few weeks, someone asks me whether AI is a bubble. Usually it's a sharp person — an investor, a board member, a fellow founder — and they ask while glancing at a stock chart that has gone vertical. It's a fair question. It's also aimed at the wrong object.
THE FUTURE IS AI-NATIVE.
LET'S BUILD IT WITH YOU.
Partner with us to design and deploy AI-native systems.